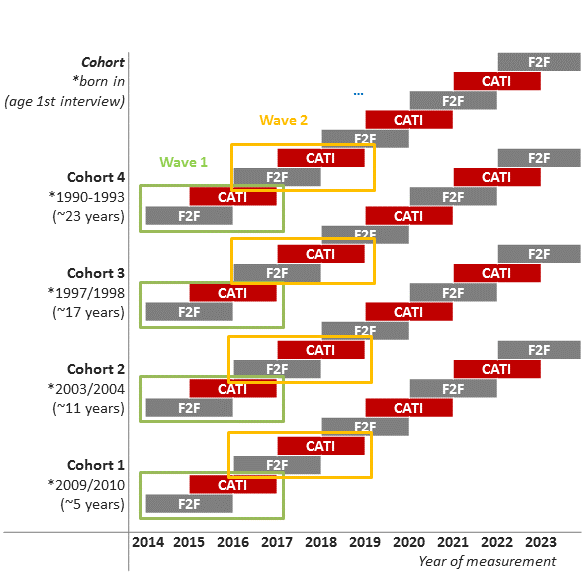
Data collection began in 2014 with a population-based sample of 4,096 twin families. The cross-sequential survey design (see Figure 2) contains four twin birth cohorts with ~1,000 same-sex (both monozygotic and dizygotic) twin pairs in each cohort.
Face-to-face interviews within the households take place every other year, and telephone interviews are conducted in the consecutive years. In the years 2020 and 2021, ➔ three additional surveys on the COVID-19 pandemic were conducted. Furthermore, from 2018 to 2024, ➔ three saliva samples were taken from the respondents. In the Face-to-face interviews data was collected using a mixed-mode design: Participants were surveyed by an interviewer (computer-assisted personal interview; CAPI), by means of questionnaires on a tablet or laptop (computer-assisted self-interview; CASI), via a paper-and-pencil interview (PAPI) and/or via online questionnaires (computer-assisted web interview; CAWI). Due to the pandemic, a new interview mode CAPI-by-Phone was introduced for the face-to-face interviews. This meant that the interviewer, who normally conducts the interview with the family face-to-face, conducted the interview over the phone. In F2F4, this was the only interview mode available. In F2F5, respondents could choose between CAPI-by-Phone and a face-to-face interview in the household.
On the one hand, these mixed modes ensured the most suitable assessment strategy for each question type, i.e. more sensitive topics were covered via CASI. On the other hand, they allowed a certain degree of flexibility for the interviewer in order to minimize the total interview duration in the households.
School reports and developmental check-up reports were scanned as part of the CAPI and encoded afterwards.
There are two characteristics of data collection and sample composition, which are briefly explained here.
First characteristic: Two subsamples
When the study was implemented, two subsamples of the initial age cohorts (consisting of twins aged about 5, 11, 17, and 23 years) were drawn, which were born in consecutive years (see Figure 2). This was necessary to achieve a sufficiently large sample size for TwinLife based on the target population of twin families in Germany.
As a result, the first subsample (Subsample a) consists of twins born in 1990/91, 1997, 2003 and 2009 and the second subsample (Subsample b) consists of twins born in 1992/93, 1998, 2004 and 2010. The subsample a) was interviewed for the first time in 2014 while subsample b) was interviewed first in 2015. Together, subsamples, a) and b) form the complete sample of TwinLife.
Identifiers for the two subsamples are recorded in variable wav0100.
Second characteristic: Two data collections are one survey wave
Face-to-face interviews (F2F) are carried out biennially in TwinLife. In the year between, a part of the sample is surveyed via telephone interviews (CATI). The main purposes of the CATI interviews are: 1) keeping in touch with the participants, 2) updating the contact information of the families (tracking), 3) collecting some complementary data that could not be surveyed in the face-to-face interview due to time restrictions, and 4) keeping track of important life events and transitions. Therefore, each F2F data collection together with the consecutive CATI data collection including both subsamples a) and b) is defined as one survey wave.
The identifiers for the survey waves are recorded in variable wav0200 and the identifiers for the type of data collection (F2F or CATI) are recorded in variable wav0300. The consecutive numbering for each data collection is recorded in variable wid (see Table 1 for an overview).
wav0200 | wav0300 | wid | wav0100 | (planned) release date |
|---|---|---|---|---|
Wave 1 | Face-to-Face 1 (F2F 1) | Data collection 1 | Subsample a Subsample b | Autumn 2017 |
Telephone interview 1 (CATI1) | Data collection 2 | Subsample a Subsample b | January 2019 | |
Wave 2 | Face-to-Face 2 (F2F 2) | Data collection 3 | Subsample a Subsample b | Spring 2020 |
Telephone interview 2 (CATI2) | Data collection 4 | Subsample a Subsample b | Winter 2020 | |
Wave 3 | Face-to-Face 3 (F2F 3) | Data collection 5 | Subsample a Subsample b | Winter 2021 |
Telephone interview 3 (CATI3) | Data collection 6 | Subsample a Subsample b | Spring 2023 | |
Wave 4 | Face-to-Face 4 (F2F 4) | Data collection 7 | Subsample a Subsample b | Spring 2024 |
Telephone interview 4 (CATI4) | Data collection 8 | Subsample a Subsample b | Spring 2024 | |
Wave 5 | Face-to-Face 5 (F2F 5) | Data collection 9 | Subsample a Subsample b | Spring 2025 |
In TwinLife, a person or family who does not participate in one or more waves is considered a temporary drop-out until they finally refuse to participate. They will then be excluded from the following waves.
Usually, there is one data release each year, including new data of either a F2F or a CATI data collection for both subsamples.